Top Web Scraping Tools in 2025

Top web scraping tools have become essential for developers, marketers, and data analysts who need structured information from websites. In 2025, the demand for smarter, more scalable, and reliable scraping tools is growing as businesses rely on real-time data for competitive advantage. Whether you are monitoring prices, collecting SEO data, or analyzing trends, choosing the right tool is vital. This guide covers the top web scraping tools in 2025, practical use cases, and recent innovations you need to know about. You’ll discover what sets each tool apart and how to match the right solution with your specific scraping needs.
Why the Top Web Scraping Tools in 2025 Matter for Data-Driven Success
Web scraping has evolved from simple scripts to complex, cloud-based systems. Developers today are not just pulling data but navigating captchas, IP bans, dynamic content, and JavaScript-heavy sites. The top web scraping tools simplify these challenges by offering APIs, browser automation, and proxy integration. These tools for developers are designed to reduce time-to-data and boost efficiency. Many also offer low-code or no-code solutions that work well for non-engineers.
Scrapy
Scrapy is a fast, open-source web crawling framework written in Python and maintained by a strong community. It has been around since 2008 and remains one of the most trusted web scraping tools for developers.
- Key Features: Asynchronous requests, robust middleware system, selectors based on XPath and CSS, auto-throttling
- Use Case: Large-scale data extraction from e-commerce sites or real estate listings
- What Sets It Apart: Extensibility and speed make it a favorite among experienced Python developers
- Recent Updates: Enhanced support for handling JavaScript-rendered content using integrations with Splash and Playwright
Octoparse
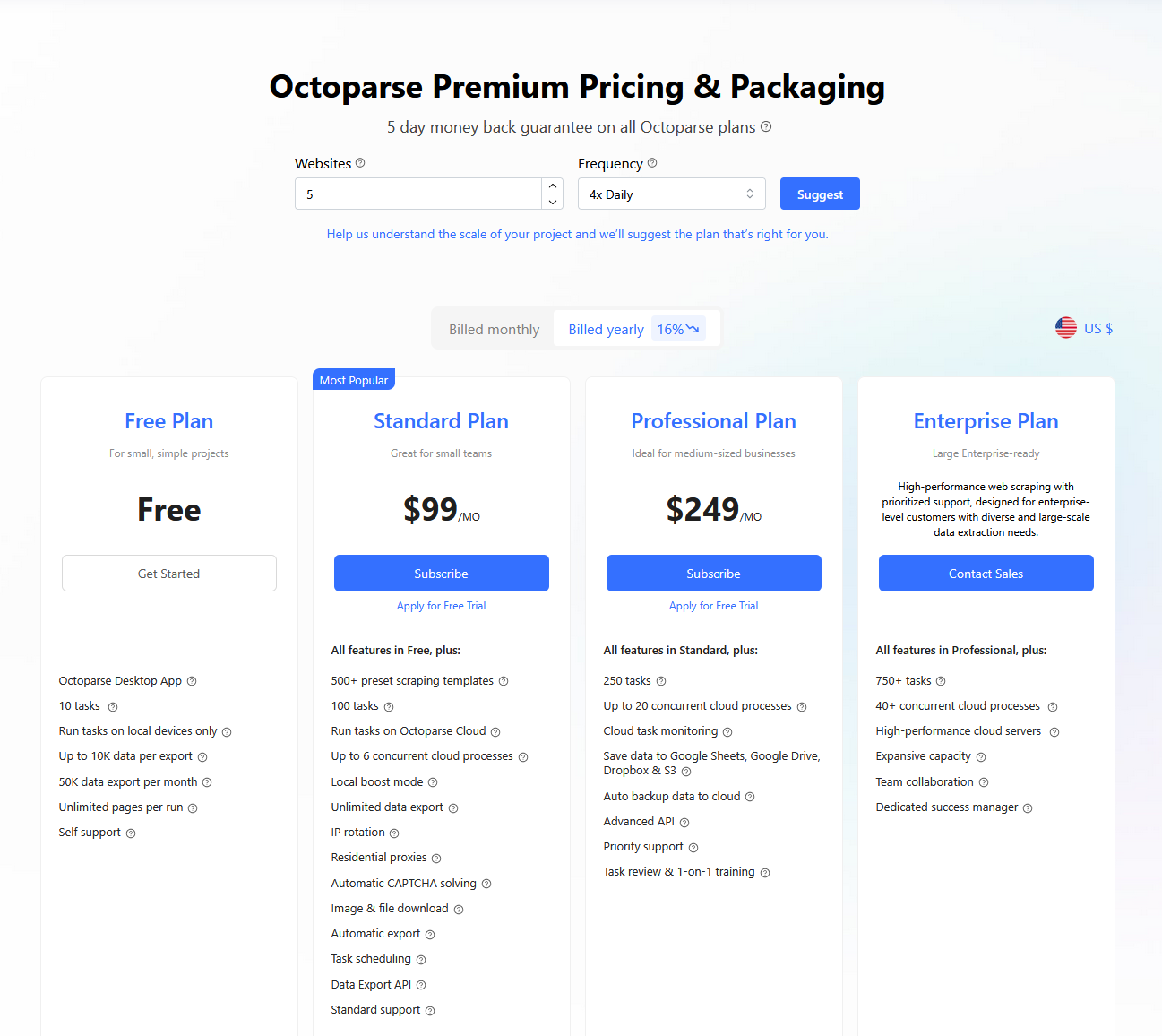
Octoparse is a no-code web scraping software designed for users with little to no programming experience. Launched in 2016, it has grown rapidly thanks to its user-friendly visual workflow.
- Key Features: Point-and-click interface, scheduled scraping, IP rotation, cloud-based storage
- Use Case: Extracting job listings or pricing data for competitor analysis
- What Sets It Apart: The intuitive visual editor makes it accessible to marketers and business users
- Recent Innovations: Smart templates for Amazon, eBay, and LinkedIn scraping
Beautiful Soup
Beautiful Soup is a Python library designed for parsing HTML and XML documents. Created by Leonard Richardson in 2004, it provides Pythonic idioms for iterating, searching, and modifying the parse tree, making it easy to extract data from web pages. Beautiful Soup is particularly useful for projects where quick turnaround and simplicity are essential.
Key features of Beautiful Soup include:
- Ease of use for beginners and rapid development
- Robust handling of poorly formed HTML
- Integration with parsers like lxml and html5lib for speed and flexibility
Beautiful Soup is best suited for small to medium-sized projects where ease of use and quick development are priorities.
Puppeteer
Puppeteer is a Node.js library from Google that provides a high-level API to control Chrome or Chromium via the DevTools Protocol. Released in 2017, it quickly became popular for headless browser automation.
- Key Features: JavaScript rendering, screenshot capture, automated form submission
- Use Case: Scraping JavaScript-heavy websites or testing front-end behavior
- What Sets It Apart: Full control of the browser environment makes it ideal for scraping dynamic content
- Recent Innovations: Seamless integration with Playwright and improved performance in headful mode
ParseHub
ParseHub is a web scraping tool that combines a user-friendly interface with powerful features to handle complex data extraction tasks. It supports dynamic websites and allows users to create workflows through a visual editor. ParseHub is suitable for both beginners and advanced users who need to collect data from various sources.
Key features of ParseHub include:
- Interactive visual selector for data extraction
- Ability to handle JavaScript and AJAX-heavy websites
- Cloud-based data storage and scheduling
ParseHub is a versatile tool that caters to users with varying levels of technical expertise.
Apify
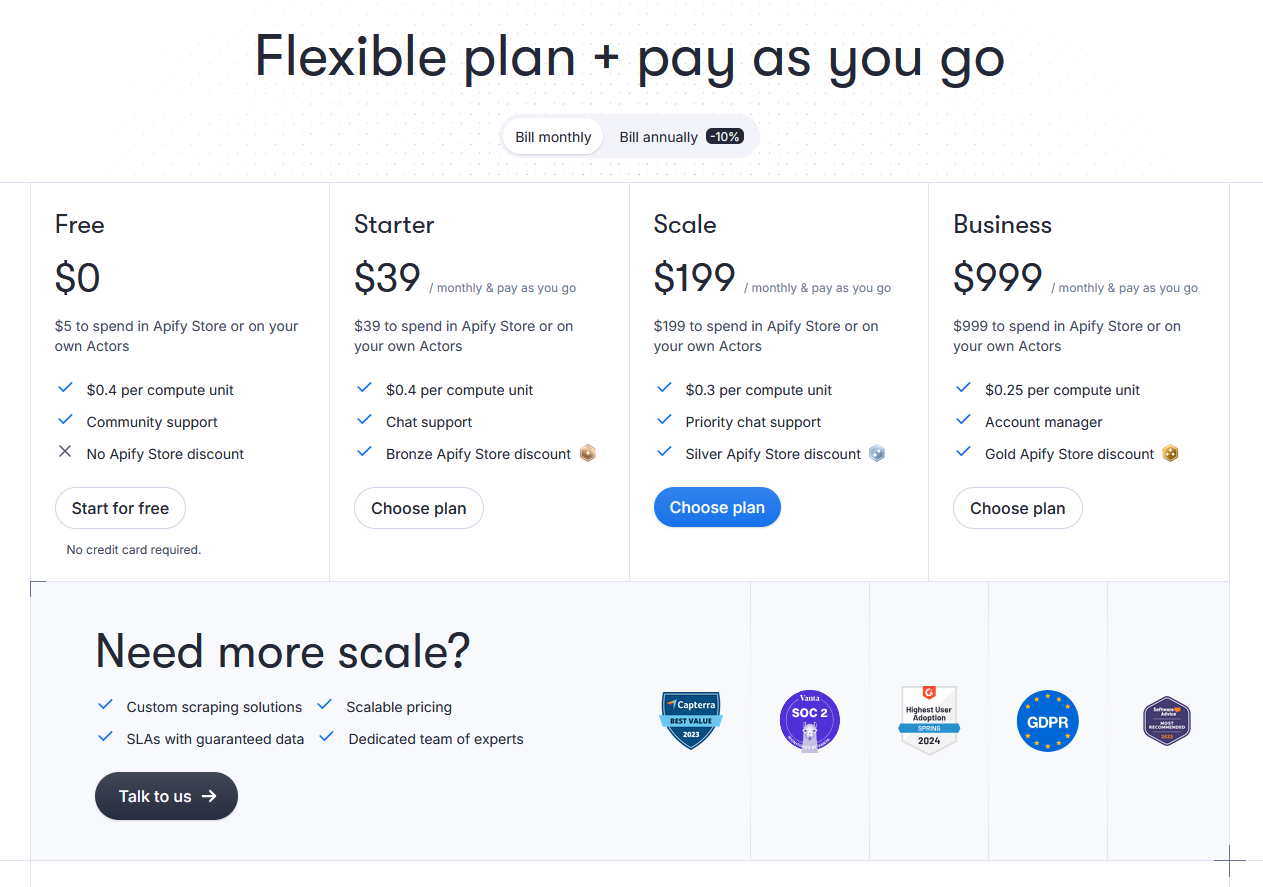
Apify is a cloud-based scraping and automation platform that supports both custom scripts and ready-to-use actors. Established in 2015, it has grown popular for its modular architecture and scalable cloud runners.
- Key Features: Actor system for running scripts, integration with Puppeteer and Playwright, storage API
- Use Case: Crawling social media feeds or automating competitor research
- What Sets It Apart: Marketplace of prebuilt solutions and seamless serverless scaling
- Recent Updates: Enhanced integrations with GPT-based analysis tools for structured data insights
Diffbot
Diffbot is an AI-powered web scraping and data extraction platform that transforms unstructured web data into structured, actionable information. It uses machine learning and natural language processing to analyze and extract data from web pages automatically. Diffbot is known for its ability to handle complex web structures and deliver high-quality data.
Key features of Diffbot include:
- Automatic entity extraction and classification
- Computer vision-based web understanding
- Structured APIs for various content types
Diffbot is ideal for enterprises and researchers who need comprehensive and accurate data extraction capabilities.
ScrapingBee

ScrapingBee is a web scraping API that handles headless browsers and proxies, allowing developers to focus on data extraction without worrying about infrastructure. It simplifies the process of scraping dynamic websites by managing browser rendering and IP rotation internally.
Key features of ScrapingBee include:
- Automatic proxy rotation and browser rendering
- Support for JavaScript-heavy websites
- Simple API integration for developers
ScrapingBee is best suited for developers who need a straightforward API to extract data from complex websites.
Common Use Cases and Real-World Applications
Understanding where top web scraping tools shine can help you choose the right one for your workflow:
- SEO Intelligence: Tools like Scrapy and Apify are used to pull SERP data, backlink profiles, and meta tags for thousands of URLs
- Market Monitoring: Octoparse and Bright Data help retailers stay ahead by scraping competitor pricing, availability, and user reviews
- Social Media Tracking: Puppeteer and Apify can fetch dynamic content from Twitter and Instagram for sentiment or trend analysis
- Academic Research: Scrapy is often used in large research projects involving citations, public records, and academic papers
- Real Estate Aggregation: Combining Bright Data’s proxy infrastructure with a Scrapy or Puppeteer script gives access to vast amounts of listing data
Tips for Using Web Scraping Tools Efficiently
- Use rotating proxies to avoid IP bans and CAPTCHA walls when scraping frequently
- Always respect robots.txt and website scraping policies to avoid legal issues
- Set rate limits and random delays to mimic human behavior and stay under the radar
- Leverage cloud-based scraping to scale jobs and free up your local resources
- Structure your data pipeline with robust error handling and logging to prevent silent failures
Choosing the Right Tool for Your Needs
Selecting the appropriate web scraping tool depends on several factors, including technical expertise, project complexity, and specific requirements. Here’s a brief guide:
- For Developers: Tools like Scrapy and Beautiful Soup offer flexibility and control for custom scraping projects.
- For Non-Programmers: Octoparse and ParseHub provide user-friendly interfaces for data extraction without coding.
- For Scalable Solutions: Apify and Diffbot are suitable for large-scale, automated data collection needs.
- For API Integration: ScrapingBee offers a simple API for developers to integrate scraping capabilities into applications.
By assessing your specific needs and evaluating the features of each tool, you can choose the most suitable web scraping solution for your projects in 2025.
Web scraping has become an essential part of modern data acquisition. Whether you’re tracking competitor prices, analyzing market trends, or automating repetitive data collection tasks, scraping is often the backbone of digital insight. However, traditional scraping can be complex and time-consuming, often requiring programming knowledge, constant upkeep to accommodate changes in website structure, and mechanisms to bypass anti-bot protections.


